Kimi K2 Thinking: China's Open-Source Agentic AI Challenges Global Frontier Models


How Moonshot AI's Trillion-Parameter Reasoning Model is Reshaping Enterprise AI Strategy, Cost Economics, and the Open-Source Frontier
Executive Overview
Bottom Line Up Front: Moonshot AI's Kimi K2 Thinking represents a watershed moment in enterprise AI adoption. Released November 6, 2025, this open-source trillion-parameter model delivers frontier-class performance on agentic reasoning and coding tasks—matching or exceeding GPT-5 and Claude Sonnet 4.5 on key benchmarks—while offering 80-90% cost reduction and full deployment flexibility. For strategic decision-makers, this signals an accelerating shift toward multi-model architectures and reduced vendor lock-in. For technical teams, it provides production-ready agentic capabilities with transparent architecture and extensive tooling support.

Market Context: The Agentic AI Inflection Point
The release of Kimi K2 Thinking arrives at a critical juncture in enterprise AI adoption. While 2024-2025 saw widespread deployment of conversational AI for content generation and analysis, the emerging paradigm centers on agentic intelligence—systems capable of autonomous multi-step reasoning, dynamic tool orchestration, and goal-directed problem-solving without constant human intervention.
Moonshot AI's entry into this space is particularly significant given the geopolitical and economic context. Despite U.S. export restrictions limiting Chinese firms' access to advanced semiconductors like NVIDIA's H100, companies including Moonshot, DeepSeek, and Alibaba's Qwen team have demonstrated that architectural innovation and efficient training methodologies can offset hardware constraints. Moonshot trained K2 Thinking using H800 GPUs—downgraded H100 variants marketed exclusively in China—yet achieved performance metrics competitive with models trained on unrestricted hardware.
Strategic Implication: Major U.S. enterprises including Airbnb are publicly adopting Chinese AI models as cost-effective alternatives to OpenAI and Anthropic. This trend suggests the AI competitive landscape is evolving from a two-horse race (OpenAI/Anthropic) toward a multi-polar ecosystem where open-source models from global labs compete on performance, cost, and deployment flexibility.
Technical Architecture: Engineering for Efficiency and Scale
Mixture-of-Experts Foundation
Core Architecture Parameters:
- Total Parameters: 1 trillion (1T), with 32 billion (32B) activated per token
- Architecture Type: Sparse Mixture-of-Experts (MoE) with 384 experts, 8 selected per token
- Layer Configuration: 61 total layers including 1 dense layer and 1 shared expert
- Attention Mechanism: Multi-head Latent Attention (MLA) with 7,168 hidden dimensions
- Activation Function: SwiGLU (Swish-Gated Linear Unit)
- Vocabulary Size: 160,000 tokens
- Context Window: 256,000 tokens
The MoE design enables K2 Thinking to maintain the representational capacity of a trillion-parameter dense model while activating only 32 billion parameters per inference step. This sparse activation strategy reduces computational overhead by approximately 97% compared to a hypothetical dense equivalent, making the model economically viable for real-world deployment despite its massive scale.
Native INT4 Quantization: A Training-Time Innovation
One of K2 Thinking's most significant technical achievements is its Quantization-Aware Training (QAT) approach. Unlike traditional quantization methods applied post-training (which often degrade model quality), Moonshot integrated INT4 weight-only quantization into the post-training phase itself. This training-time intervention allows the model to "learn" how to perform effectively within INT4 constraints, achieving:
- 2× inference speed improvement in low-latency mode
- Lossless accuracy preservation across benchmarks compared to higher-precision variants
- 594GB model footprint (down from 1.03TB for the base Kimi K2 model)
- Reduced GPU memory requirements, enabling deployment on more accessible hardware
All published benchmark results for K2 Thinking reflect INT4 performance, ensuring that reported metrics accurately represent real-world deployment scenarios rather than idealized higher-precision configurations.
Test-Time Scaling: Reasoning Depth as a Controllable Parameter
K2 Thinking implements test-time scaling, a technique that dynamically adjusts both reasoning token budget and tool-calling depth based on task complexity. Rather than applying a fixed computational effort to all queries, the model adaptively allocates more "thinking time" and tool invocations to harder problems. This approach mirrors human cognitive strategies and enables:
- Adaptive resource allocation: Simple queries receive rapid responses; complex tasks receive extended deliberation
- Heavy Mode operation: For maximum accuracy, K2 can run eight parallel reasoning trajectories and aggregate results
- Token budget flexibility: Reasoning budgets range from 32K tokens (long-form writing) to 128K tokens (complex coding tasks)
Agentic Tool Orchestration: The Core Differentiator
Unlike traditional language models that require explicit human guidance at each step, K2 Thinking is trained end-to-end to interleave chain-of-thought reasoning with function calling. This enables the model to autonomously:
- Decompose high-level goals into actionable subtasks
- Select appropriate tools from available APIs (web search, code execution, data retrieval, etc.)
- Execute sequential tool calls, maintaining logical coherence across 200-300 steps
- Synthesize intermediate results into final outputs
- Adapt hypotheses based on tool feedback, dynamically refining approaches
This agentic capability positions K2 Thinking for applications in autonomous research, multi-step coding assistance, financial analysis workflows, and enterprise automation—domains where prior models struggled with context management and error propagation across extended interaction chains.
Benchmark Performance: Comparative Analysis Against Frontier Models
Moonshot AI's published benchmarks position K2 Thinking competitively with—and in some cases superior to—leading proprietary models. However, it's critical to interpret these results within appropriate context: no single model dominates across all task categories, and real-world performance depends heavily on specific use cases, deployment configurations, and integration quality.
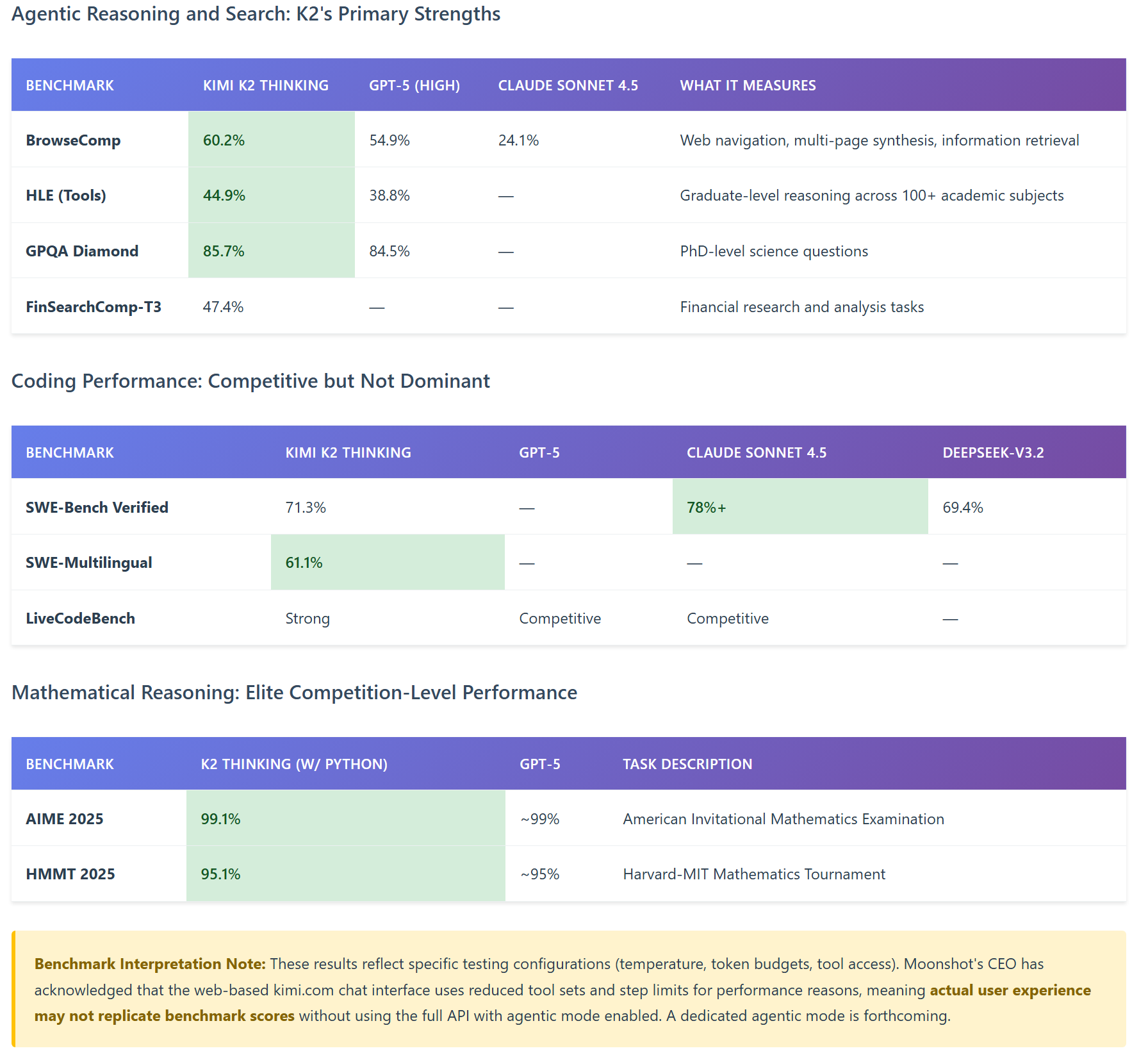
What the Benchmarks Really Tell Us
The comparative data reveals three critical insights:
- Domain-Specific Excellence: K2 Thinking excels at agentic search and web-based reasoning tasks, outperforming GPT-5 by significant margins on BrowseComp (60.2% vs. 54.9%). This reflects its training optimization for tool orchestration and long-horizon reasoning.
- Competitive Parity on Core Tasks: On mathematical reasoning and general knowledge tasks, K2 Thinking achieves near-parity with GPT-5, suggesting that open-source models have reached functional equivalence with proprietary alternatives for many enterprise use cases.
- Claude's Coding Advantage: Claude Sonnet 4.5 maintains a lead on software engineering benchmarks (SWE-Bench Verified), indicating that Anthropic's specialized coding training remains best-in-class for pure software development tasks. However, K2's 71.3% score is production-ready for many applications.
Economic Analysis: Total Cost of Ownership and Strategic Implications
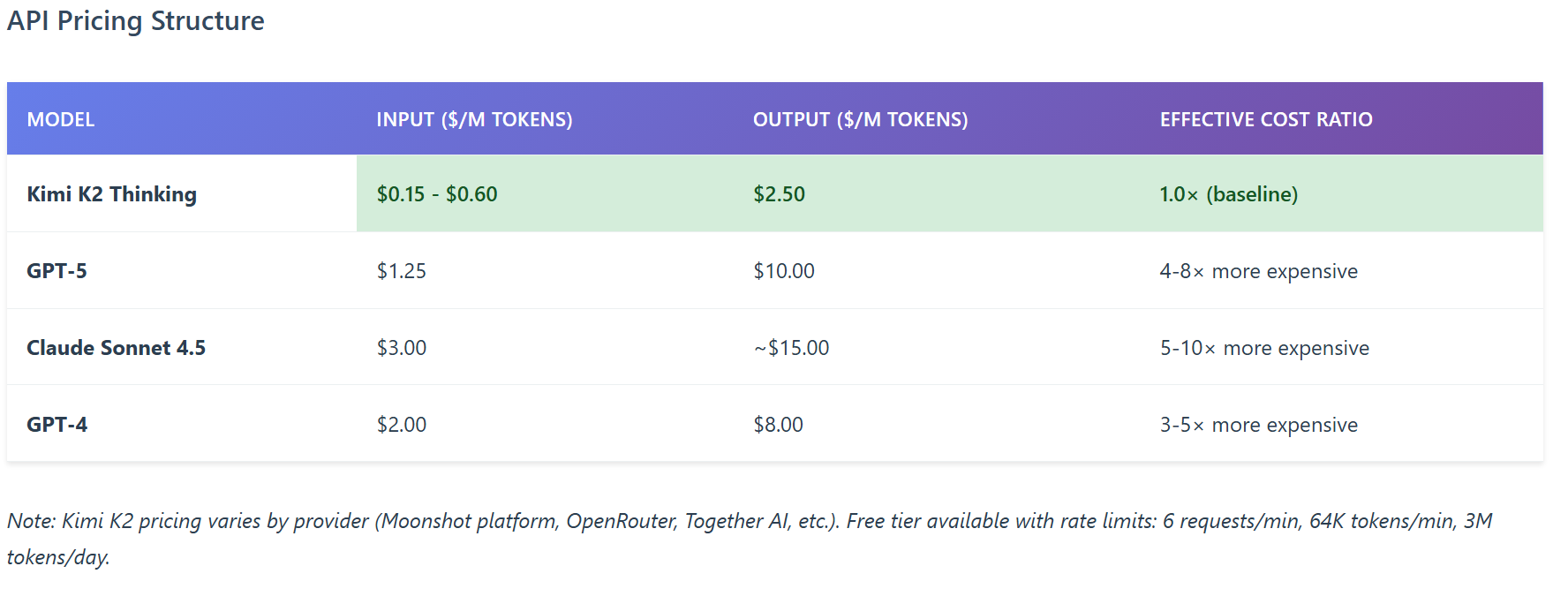
Training Cost Controversy and Implications
The widely reported $4.6 million training cost—which would contrast dramatically with OpenAI's multi-billion dollar investments—has been contested by Moonshot's CEO Yang Zhilin. In a Reddit AMA, Yang stated: "It is hard to quantify the training cost because a major part is research and experiments. This is not an official number."
Regardless of the precise figure, the strategic narrative remains compelling: Chinese AI labs are demonstrating that frontier-class performance can be achieved with:
- Export-restricted hardware (H800 GPUs vs. H100s)
- Efficient architectural choices (sparse MoE, quantization-aware training)
- Open-source distribution models (Modified MIT License with commercial attribution clause)
Total Cost of Ownership Scenarios
For a typical enterprise AI workload processing 1 billion tokens monthly (500M input, 500M output), the cost comparison is stark:
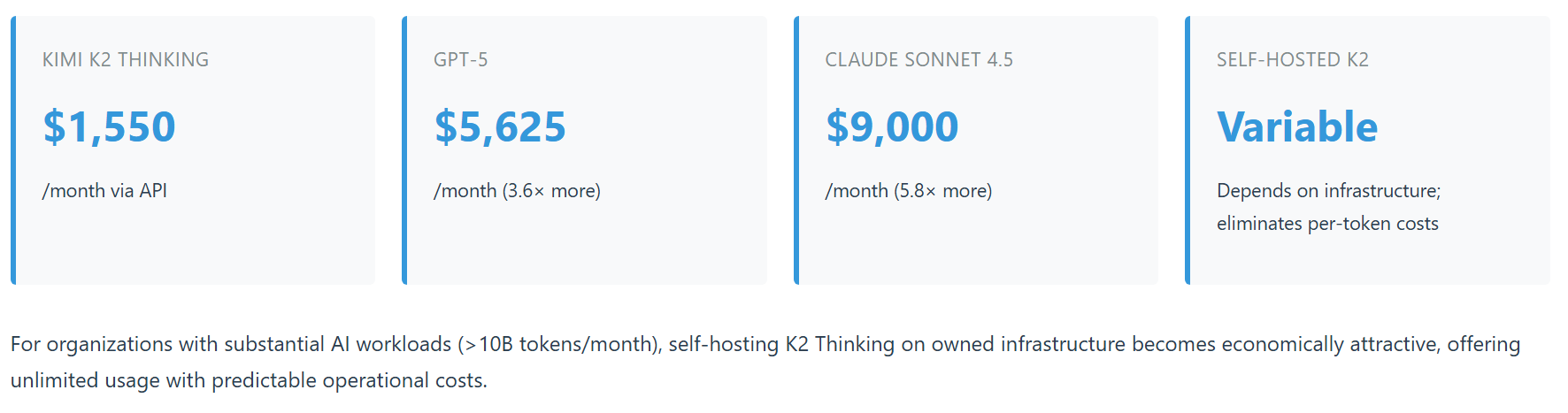
Strategic Implications by Stakeholder
C-Suite and Strategic Decision-Makers
Key Takeaways:
- Multi-Model Strategy Becomes Table Stakes: K2 Thinking's performance demonstrates that no single vendor dominates across all use cases. Best-in-class enterprises will deploy task-specific model portfolios: Claude for coding, GPT-5 for conversational AI, K2 for agentic workflows, etc.
- Vendor Lock-In Risk Mitigation: Open-source alternatives reduce negotiating leverage dependency on OpenAI and Anthropic. K2's OpenAI-compatible API simplifies migration and enables fallback architectures.
- Geopolitical AI Diversification: As U.S.-China tech tensions persist, maintaining access to both Western and Chinese AI ecosystems provides strategic optionality. K2's open-source nature enables deployment regardless of export control evolution.
- Cost Optimization Without Quality Sacrifice: For workloads suitable to K2's strengths (research automation, data synthesis, long-form analysis), 80-90% cost reduction is achievable while maintaining frontier-class performance.
- Data Sovereignty and Privacy: Self-hosted K2 deployment enables GDPR/CCPA compliance and eliminates third-party data exposure—critical for regulated industries (healthcare, finance, defense).
Action Items:
- Commission 90-day pilot comparing K2 against incumbent models on 3-5 representative enterprise workflows
- Evaluate TCO for self-hosted K2 vs. API consumption at current and projected usage scales
- Assess regulatory/compliance implications of Chinese AI model adoption within your jurisdiction
- Develop multi-model orchestration strategy with provider-agnostic abstraction layer
Technical Engineers and ML Practitioners
Key Takeaways:
- Production-Ready Tooling: K2 Thinking supports industry-standard inference engines (vLLM, SGLang, KTransformers) with comprehensive documentation and OpenAI-compatible APIs. Integration complexity is minimal for teams with existing LLM infrastructure.
- Hardware Requirements: While the 1T parameter scale sounds daunting, INT4 quantization and MoE sparsity make deployment feasible on single high-end GPUs (A100, H100) or multiple consumer-grade units (RTX 4090, etc.). The 594GB model footprint fits on modern GPU memory configurations.
- Agentic Workflow Design: K2's 200-300 sequential tool call capability enables genuinely autonomous agents. Design patterns should emphasize tool permission boundaries, context summarization strategies (to manage 256K token windows efficiently), and human-in-the-loop checkpoints for high-stakes decisions.
- Transparent Reasoning Traces: K2 exposes its chain-of-thought reasoning via dedicated API fields, enabling debugging, interpretability analysis, and reasoning quality assessment—capabilities often opaque in proprietary models.
- Fine-Tuning and Customization: Full model weights enable domain-specific fine-tuning, LoRA adaptation, and architectural experimentation—impossible with closed models.

Deployment Recommendations:
- For API Integration: Start with OpenRouter or Moonshot platform API for rapid prototyping. Implement retry logic and fallback to GPT-5/Claude for robustness.
- For Self-Hosting: Use vLLM with INT4 support on 1-2× A100 (80GB) or H100 GPUs. Implement request queuing to manage concurrent load.
- For Agentic Applications: Design tool permissions carefully. K2's autonomous tool selection is powerful but requires governance frameworks to prevent unintended actions.
Academics and AI Researchers
Key Takeaways:
- Reproducibility and Transparency: K2's open weights, published architecture specifications, and detailed benchmark methodologies enable rigorous scientific evaluation—a stark contrast to proprietary models' opacity.
- Test-Time Scaling Research: K2 Thinking provides a production-scale testbed for investigating adaptive computation allocation, reasoning token budgets, and tool-use optimization strategies.
- Comparative Model Studies: K2 enables East-West AI development philosophy comparisons: Chinese labs' emphasis on efficiency and open-source accessibility vs. Western labs' focus on pure performance scaling and controlled access.
- Agentic AI Safety: K2's 200-300 step autonomous tool orchestration raises critical questions about error propagation, goal misalignment, and safety verification in extended-horizon systems. The model provides a research platform for exploring these challenges.
- Benchmark Evolution: K2's performance on HLE (44.9%), BrowseComp (60.2%), and other emerging benchmarks highlights the need for evaluation frameworks that capture agentic capabilities beyond static Q&A tasks.
Research Opportunities:
- Quantization-Aware Training Analysis: How does K2's INT4 QAT approach compare to post-training quantization methods in accuracy/efficiency tradeoffs?
- Tool Use Stability Studies: What mechanisms enable K2 to maintain coherence across 200-300 sequential tool calls? How does performance degrade at extreme lengths?
- Cross-Cultural Bias Analysis: Do Chinese-trained models exhibit different bias patterns compared to Western counterparts? What training data differences drive these variations?
- Agentic Safety Frameworks: How should we design guardrails, monitoring, and kill-switch mechanisms for autonomous agents with extended decision-making authority?
Limitations, Risks, and Considerations
Technical Limitations
- Inference Latency: K2 Thinking's extended reasoning processes result in longer response times compared to standard models—acceptable for research/analysis tasks but potentially problematic for real-time applications.
- Context Management: While 256K tokens is impressive, managing context efficiently across multi-hundred-step workflows requires careful summarization strategies. The model's simple "hide previous tool outputs" approach when exceeding context limits is naive.
- Not Universally Superior: Claude Sonnet 4.5 outperforms K2 on software engineering tasks; GPT-5 excels at conversational fluency. K2 is best for agentic reasoning, not all workloads.
- Heavy Mode Cost: Running 8 parallel reasoning trajectories dramatically increases compute requirements, potentially negating economic advantages.
Enterprise Risk Considerations
- Geopolitical Uncertainty: U.S. organizations must assess regulatory risk of adopting Chinese AI technologies, particularly for government/defense applications or ITAR-controlled contexts.
- Model Provenance and Backdoor Risks: Open-source models require security audits to verify absence of malicious code, data exfiltration mechanisms, or hidden biases.
- Support and Maintenance: Moonshot's long-term commitment to K2 maintenance, security patching, and model updates is uncertain compared to established vendors' enterprise SLAs.
- Hallucination and Reliability: Like all LLMs, K2 can generate plausible-sounding but factually incorrect outputs. Extended agentic workflows amplify error propagation risks.
Licensing Considerations
K2 Thinking is released under a Modified MIT License with a key commercial clause: companies generating over $20 million in monthly revenue or serving more than 100 million monthly active users must prominently display "Kimi K2" attribution. This requirement may complicate white-label or B2B SaaS applications where end-users should remain unaware of underlying model infrastructure.
The Road Ahead: Implications for AI Industry Evolution
Accelerating Open-Source Convergence
K2 Thinking's November 6, 2025 release followed MiniMax's M2 model by just one week—and M2 itself had claimed "best open LLM" status. This rapid cadence of frontier-class open releases signals an inflection point: the performance gap between proprietary and open-source models is collapsing faster than most analysts predicted.
Within six months, the open ecosystem has produced:
- DeepSeek R1 (reasoning model competitive with OpenAI o1)
- MiniMax M2 (near-GPT-5 performance on agentic tasks)
- Kimi K2 Thinking (surpassing GPT-5 on key benchmarks)
This trend pressures proprietary labs to justify pricing premiums through:
- Superior user experience (UI/UX, integration ecosystems)
- Enterprise support and SLAs (uptime guarantees, dedicated assistance)
- Continued performance leadership (though the lead time is shrinking)
- Specialized capabilities (multimodal understanding, safety guarantees)
The Multi-Polar AI Ecosystem
The narrative of U.S. AI dominance is evolving into a multipolar landscape:
- United States: OpenAI, Anthropic, Google, Meta (open-source Llama)
- China: DeepSeek, Moonshot (Kimi), Alibaba (Qwen), Tencent, Baidu
- Europe: Mistral AI, emerging national AI initiatives
For enterprises, this diversification is strategically beneficial—reducing concentration risk and increasing competitive pressure that drives innovation and cost efficiency. However, it also introduces complexity in vendor management, compliance, and architectural integration.
The Agentic Paradigm Shift
K2 Thinking exemplifies the industry's shift from conversational AI to agentic AI. Goldman Sachs' pilot of the autonomous coder Devin to create "hybrid workforces" of human engineers supervising AI agent fleets represents this paradigm in action.
The implications are profound:
- For Software Engineering: AI agents handle routine implementation; humans focus on architecture, requirements, and creative problem-solving
- For Research: Autonomous literature review, hypothesis generation, and experiment design become feasible
- For Business Operations: End-to-end workflow automation (e.g., "research competitors, draft competitive analysis, schedule stakeholder briefing") without manual intervention
K2's 200-300 sequential tool call capability makes such scenarios practical rather than aspirational.
Conclusion: Strategic Recommendations
Kimi K2 Thinking represents more than an impressive technical achievement—it signals a fundamental restructuring of the AI industry's competitive dynamics. The key strategic insights:
- Performance Parity Achieved: Open-source models now match or exceed proprietary alternatives on many enterprise tasks. The "frontier" is becoming crowded.
- Economic Viability Shifts: 80-90% cost reductions without quality sacrifice make open models economically compelling for volume workloads.
- Agentic Capabilities Mature: 200-300 step autonomous workflows transition from research prototypes to production tools, enabling new classes of applications.
- Geopolitical Complexity Increases: Chinese AI models' rapid advancement forces U.S. organizations to balance performance/cost benefits against regulatory and strategic risks.
- Multi-Model Future is Inevitable: No single model dominates across all dimensions. Winners will be organizations that orchestrate diverse models optimally.
The Bottom Line: Kimi K2 Thinking is not a niche research project—it's a production-ready alternative that challenges the assumption that frontier AI requires closed, expensive, U.S.-based providers. For strategic leaders, the question is no longer "if" to adopt open-source AI, but "how quickly" and "which workflows first."
References and Further Reading
- Moonshot AI Official Site: Kimi K2 Thinking Technical Documentation
- Hugging Face Model Repository: moonshotai/Kimi-K2-Thinking
- CNBC: "Alibaba-backed Moonshot releases new AI model Kimi K2 Thinking" (November 6, 2025)
- VentureBeat: "Moonshot's Kimi K2 Thinking emerges as leading open source AI" (November 2025)
- The Decoder: "Moonshot AI's Kimi K2 Thinking sets new agentic reasoning records" (November 2025)
- SiliconANGLE: "Moonshot launches open-source Kimi K2 Thinking AI" (November 7, 2025)
- DataCamp: "Kimi K2 Thinking: Open-Source LLM Guide, Benchmarks, and Tools" (November 2025)
- Nathan Lambert (Interconnects): "5 Thoughts on Kimi K2 Thinking" (November 2025)
- Recode China AI: "Kimi K2 Thinking: The $4.6M Model Shifting AI Narratives" (November 2025)
- Simon Willison: "Kimi K2 Thinking" (Technical Analysis, November 6, 2025)
- MarkTechPost: "Moonshot AI Releases Kimi K2 Thinking" (November 2025)
- Yicai Global: "Moonshot AI's CEO Says Reported USD4.6 Million Cost 'Isn't Official'" (November 2025)
- OpenRouter API Documentation: Kimi K2 Thinking API Access
- Together AI: Kimi K2 Thinking Model Documentation
- Artificial Analysis: Kimi K2 Thinking - Intelligence, Performance & Price Analysis
Document Information: This technical analysis was prepared for strategic decision-makers, technical practitioners, and AI researchers. Data current as of November 14, 2025. For questions or collaboration inquiries regarding enterprise AI strategy and implementation, contact your AI governance team.
Disclaimer: This document provides informational analysis for strategic planning purposes. Benchmark results reflect specific testing configurations and may not represent all real-world scenarios. Organizations should conduct independent evaluation for their specific use cases, compliance requirements, and risk tolerance.