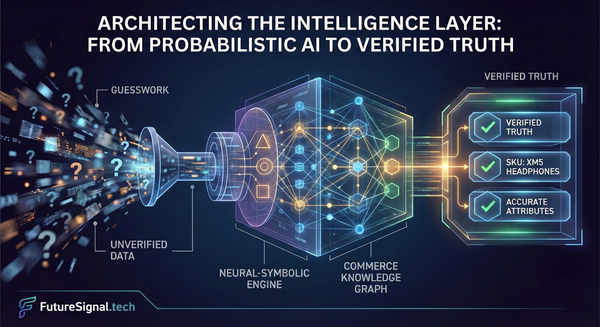
I Shipped a Search Upgrade That Improved Nothing. Here's What I Built Next.

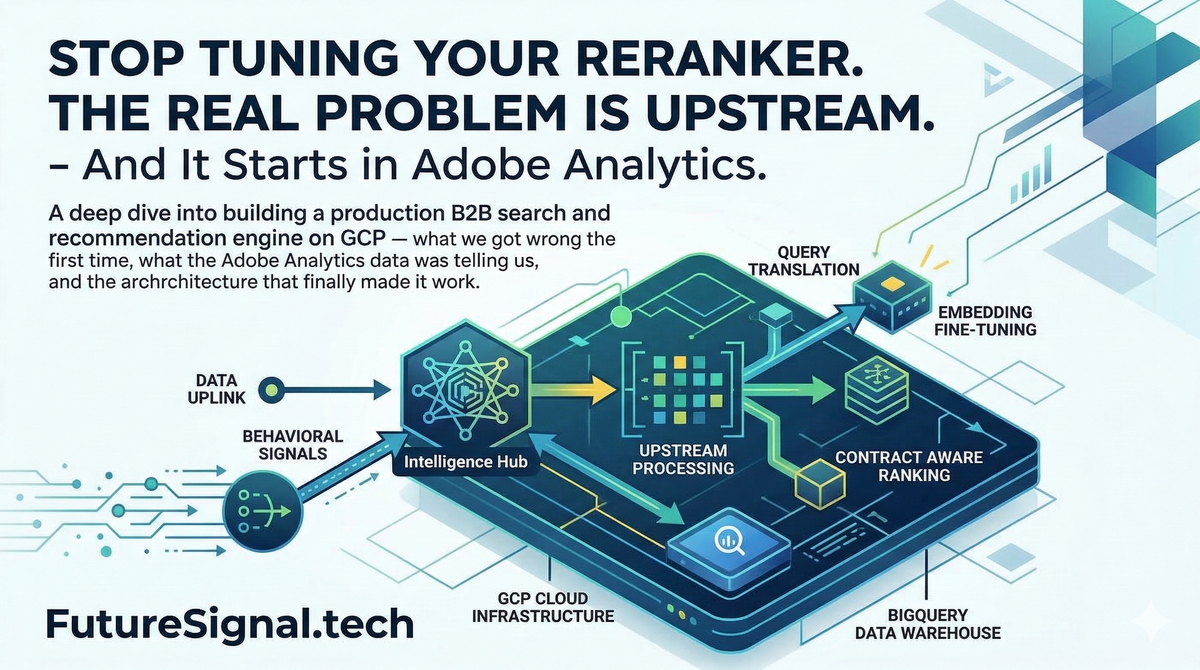
How Adobe Analytics behavioral data, Vertex AI, BigQuery, and Gemini combine into a B2B search engine that optimizes for revenue — not clicks.
How I built a production B2B search and recommendation engine on GCP — what we got wrong the first time, what the Adobe Analytics data was telling us the whole time, and the architecture that finally made it work.
Let me tell you about a moment that stuck with me.
We had just shipped what we thought was a genuinely good search upgrade. New reranker, cleaner taxonomy mappings, solid offline eval numbers. The A/B test showed an 11% lift in click-through rate. We shipped it. The team was pleased. I was pleased.
Six months later I was in a room with a VP of Commerce, a slide on the screen showing conversion rate flat for two quarters, and a very reasonable question: "What exactly did that search project improve?"
The answer, it turned out, was clicks. We had built a model that was excellent at getting buyers to click things. We had not built a model that got them to buy things. In B2B, those are two completely different populations. A procurement manager clicking a result and a procurement manager submitting a purchase order are separated by an approval chain, a compliance checklist, a vendor contract, and sometimes a six-week lead time. Our model had learned none of that.
The session data was in Adobe Analytics the whole time. Every search, every click, every order, every session that ended in silence. We were not reading it at the resolution that mattered.
That is the B2B discovery gap — not a model problem. An architecture and data problem, hiding behind metrics that look fine until someone asks about revenue. This article is what I wish I had read before we built version one.
The Question Nobody Asks First
When I join a team trying to improve B2B search, the first question is almost always: which model should we use? Transformers? Bi-encoder? Fine-tuned BERT? The conversation jumps straight to the algorithm.
I have learned to stop that conversation and ask a different question first: do we actually have the behavioral data we need, in a form we can train on?
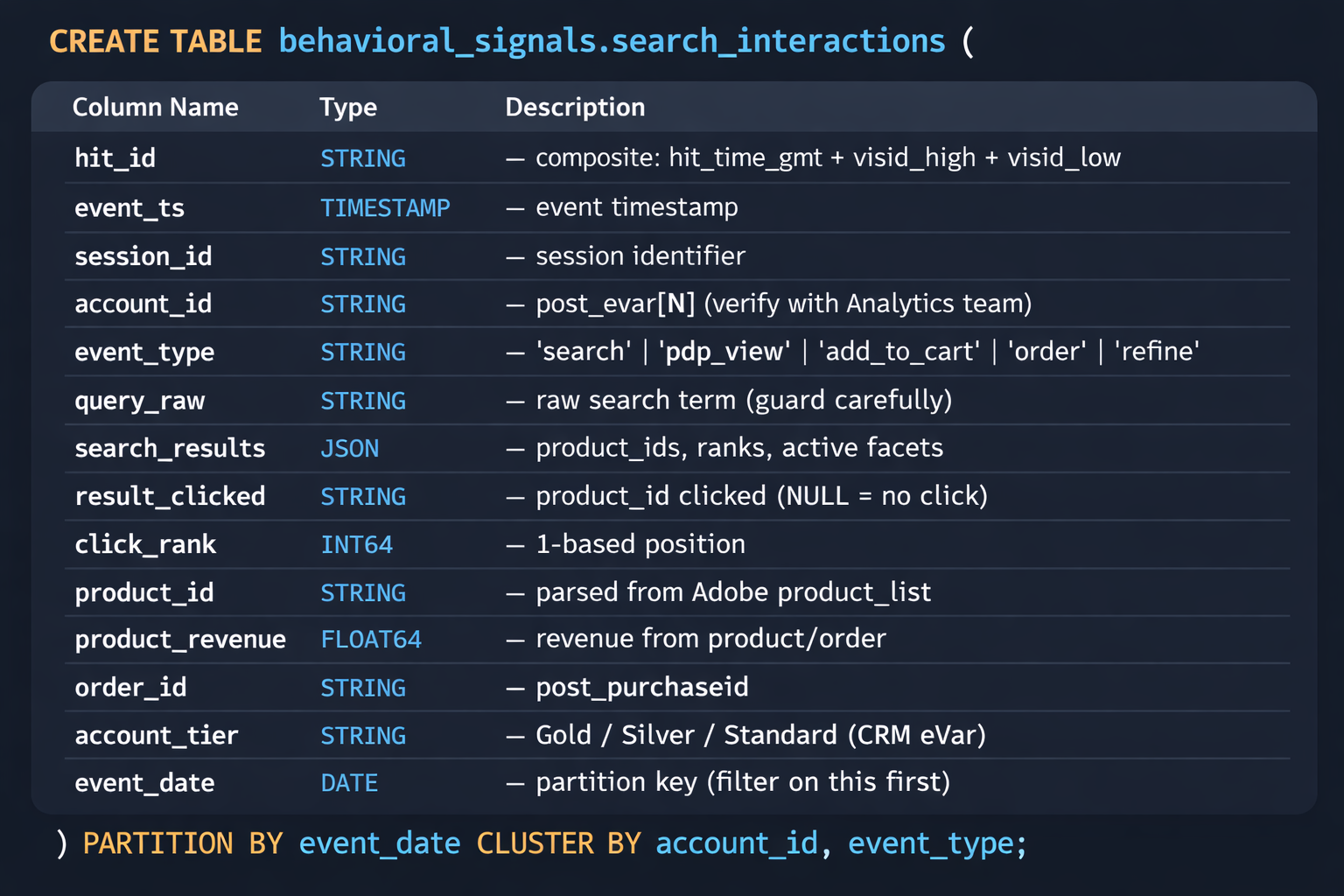
The answer is almost always: yes, sort of, buried. Adobe Analytics is sitting on everything. Every query string typed into your platform. The exact result set shown for that query. Which result was clicked and at what rank. Add-to-quote events. Order confirmations with full line-item detail. Account ID if your implementation passes it via an authenticated eVar.
The problem is that this data was instrumented for marketing analytics. The resolution is there. The schema is not organized for ML training. And most of the time, nothing is connected to the BigQuery warehouse where your order and catalog data lives.
The full technology map before a single model gets touched:
|
Layer |
What It Does |
GCP Technology |
|
Behavioral
Capture |
Every user interaction —
search, click, cart, order |
Adobe
Analytics + Adobe Launch |
|
Signal
Pipeline |
Stream AA events into GCP
continuously |
AADF → Cloud
Storage → Dataflow |
|
Behavioral
Warehouse |
Queryable history of all
buyer interactions |
BigQuery
(partitioned event tables) |
|
Embedding
Store |
Domain-fine-tuned product
vectors |
Vertex AI
Vector Search (ScaNN) |
|
Query
Intelligence |
Convert raw queries to
structured intent |
Gemini Flash
(Vertex AI) |
|
Feature
Serving |
Account signals at ranking
time, <5ms |
Vertex AI
Feature Store (Bigtable-backed) |
|
Recommendation |
Procurement pattern modeling |
BigQuery ML +
GNN on Vertex AI |
|
Grounded
Generation |
Context-aware result
explanations |
Vertex AI
Agent Builder + Gemini Pro |
|
Evaluation |
Commercial outcome metrics |
BigQuery
materialized views |
Getting Adobe Analytics Into BigQuery — The Part Nobody Documents
This took us longer than it should have. I am going to be direct about that.
The Adobe Analytics Data Feed exports every server call as a flat file. One row per hit. post_evar23. post_prop7. event_list. That is what the raw feed looks like. Nobody ever fully documents the eVar mapping. I have had this exact conversation at multiple companies — sitting with the Analytics team, reconstructing which eVar holds the account ID, which prop carries the search term, which event code fires on an order confirmation. The documentation that exists is usually from two product managers ago and references a taxonomy that changed eighteen months back. Plan for this. It is not fast.
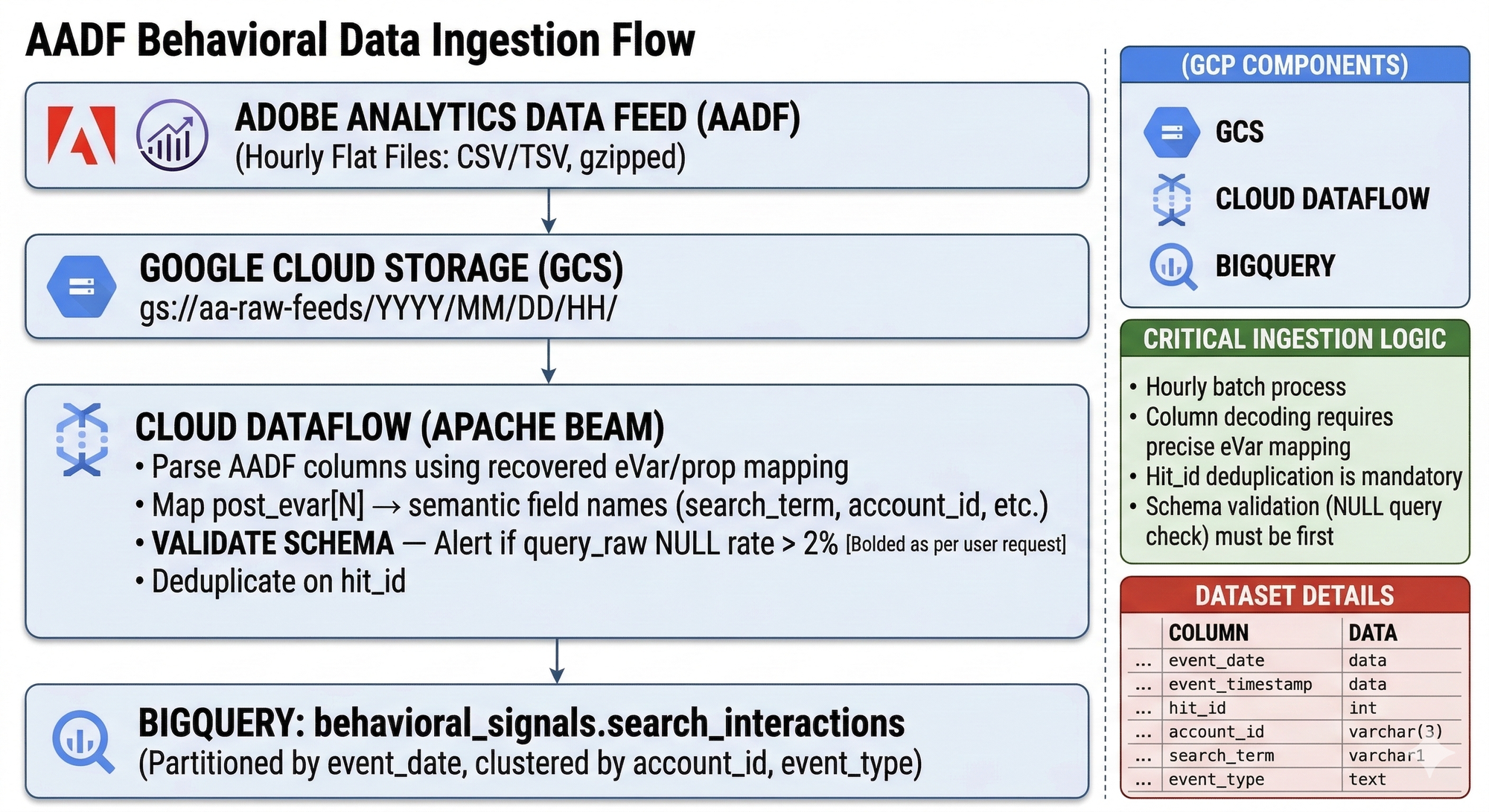
The schema validation step in Dataflow is not optional. Add it on day one. Here is why: we did not add it on day one. About eight weeks into production, the Analytics team reassigned the eVar that carried our search term to a new campaign variable. The Dataflow pipeline kept running, writing NULL into query_raw without complaint. We discovered it when the triplet mining query returned 40% NULLs. We had been training on garbage for nearly two months and the model metrics showed nothing obviously wrong until they did — all at once.
Build the session reconstruction view next. Run it on your existing Adobe Analytics data before you do anything else. Look at the ordered_from_results field. If more than 15% of your converted sessions show FALSE, you have a retrieval problem. No reranker fixes a retrieval failure. Ours was 22% when we first ran it. Uncomfortable to show to leadership. Also the number that unlocked the investment to fix the retrieval layer.
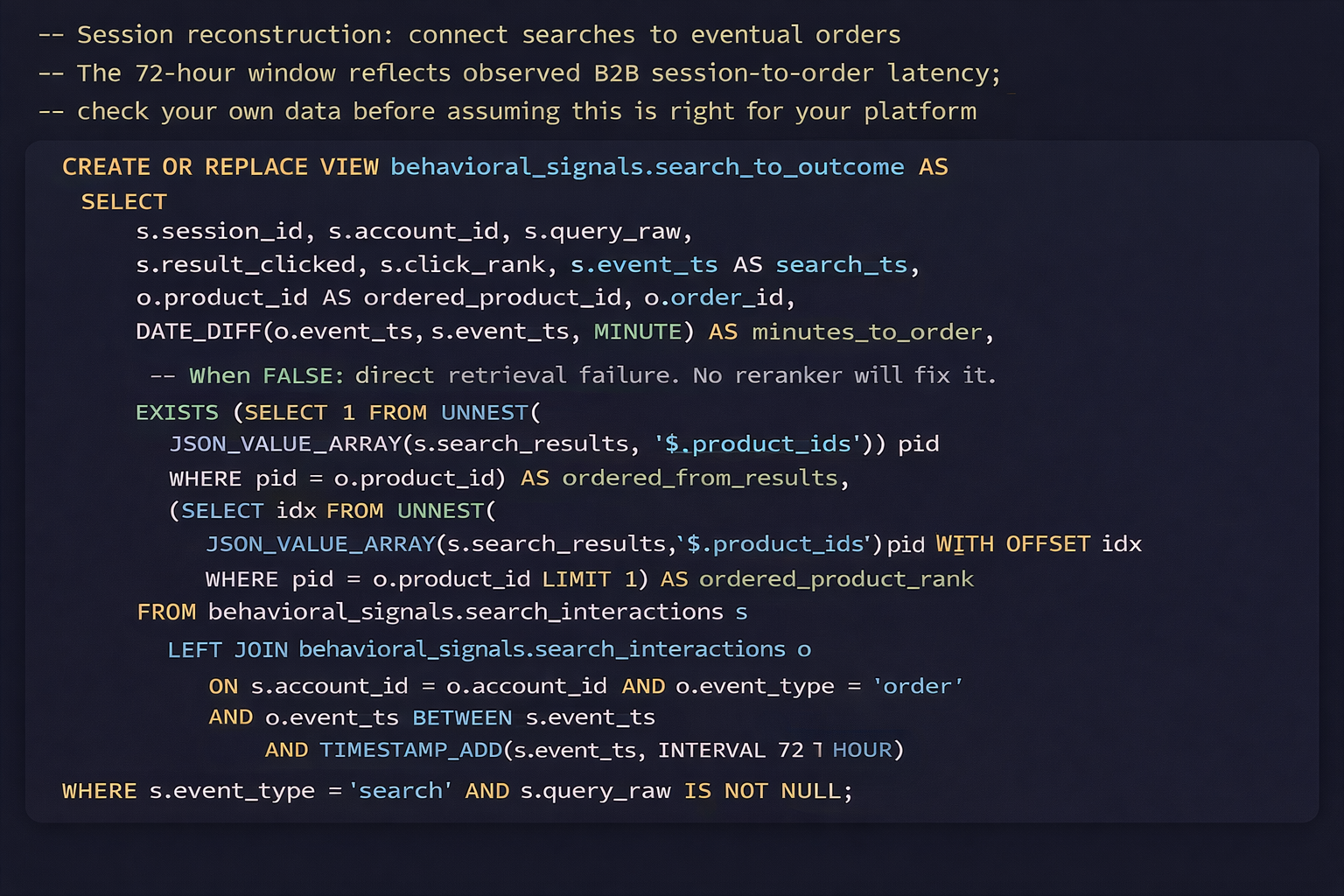
Why Your Embedding Model Does Not Know What 400G Means
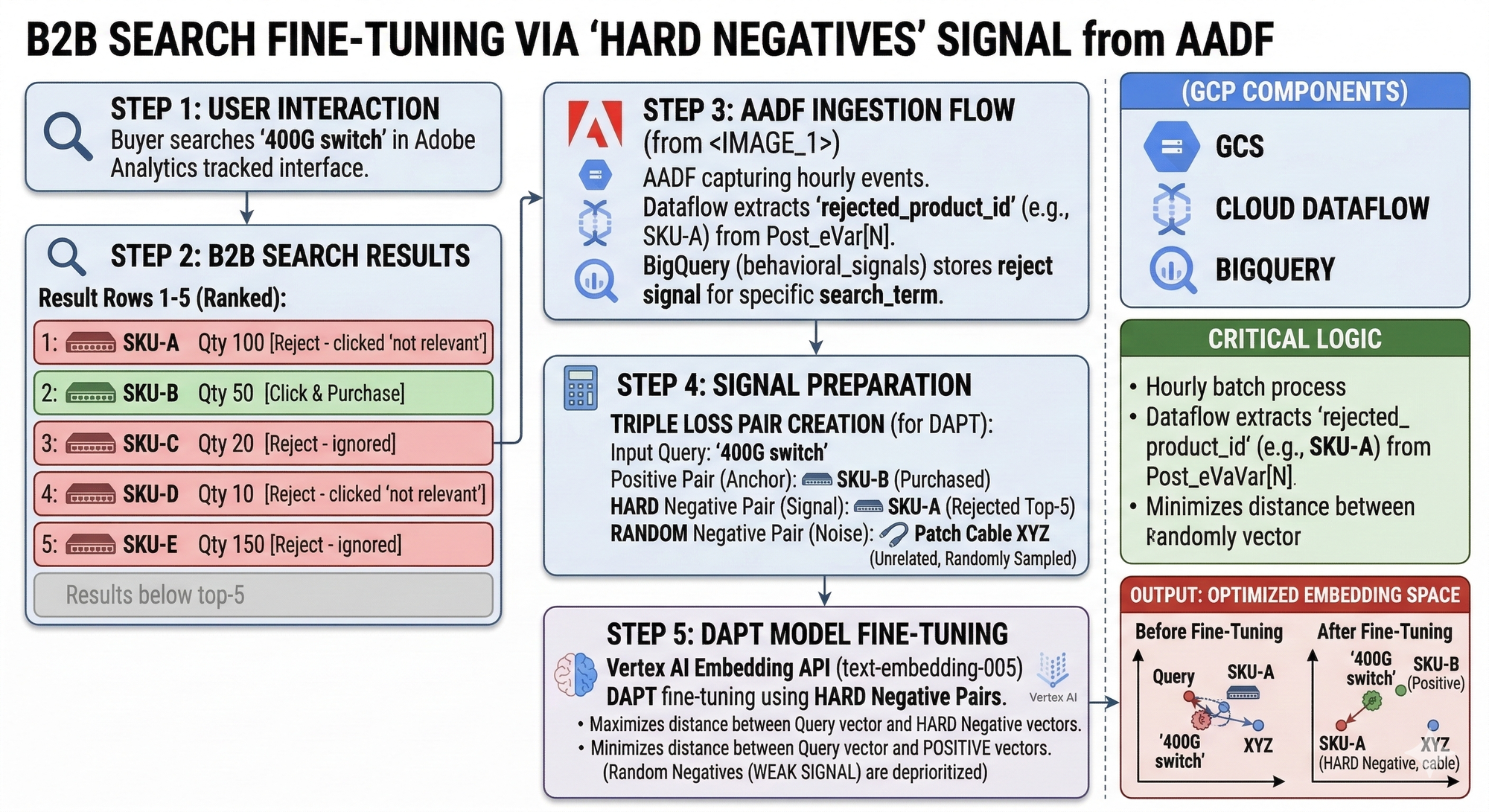
General-purpose embedding models fail on dense technical catalogs in a specific and predictable way. We shipped text-embedding-004 against our catalog and felt good about the cosine similarity numbers in our offline eval. Then we looked at what the model thought was similar to a query for "fiber channel HBA card". Optical transceivers. Patch cables. The model had no idea. The surface token overlap between "fiber channel" and "fiber optic" was doing enormous damage.
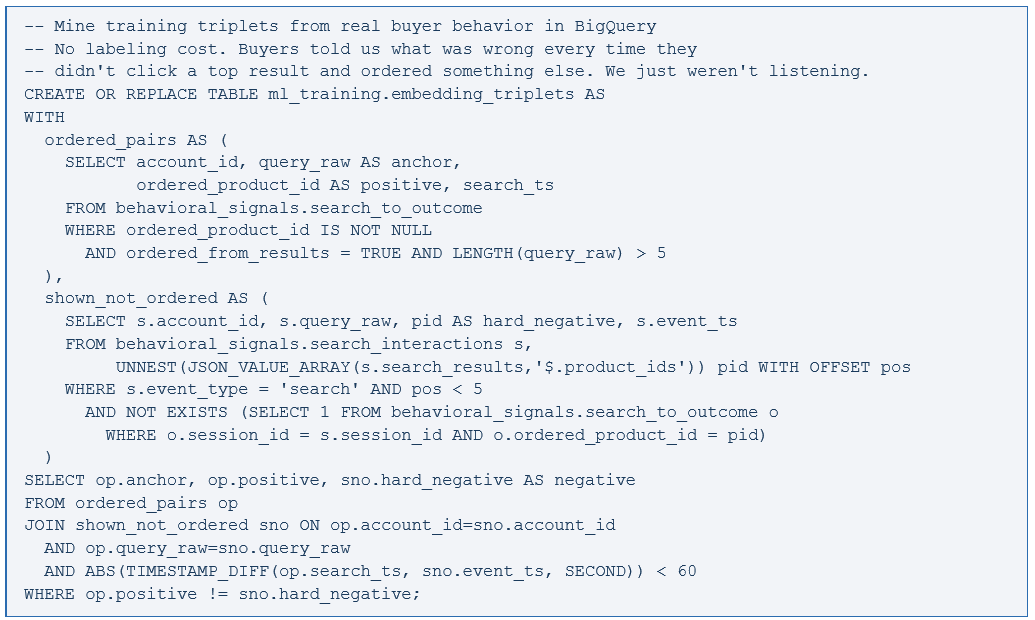
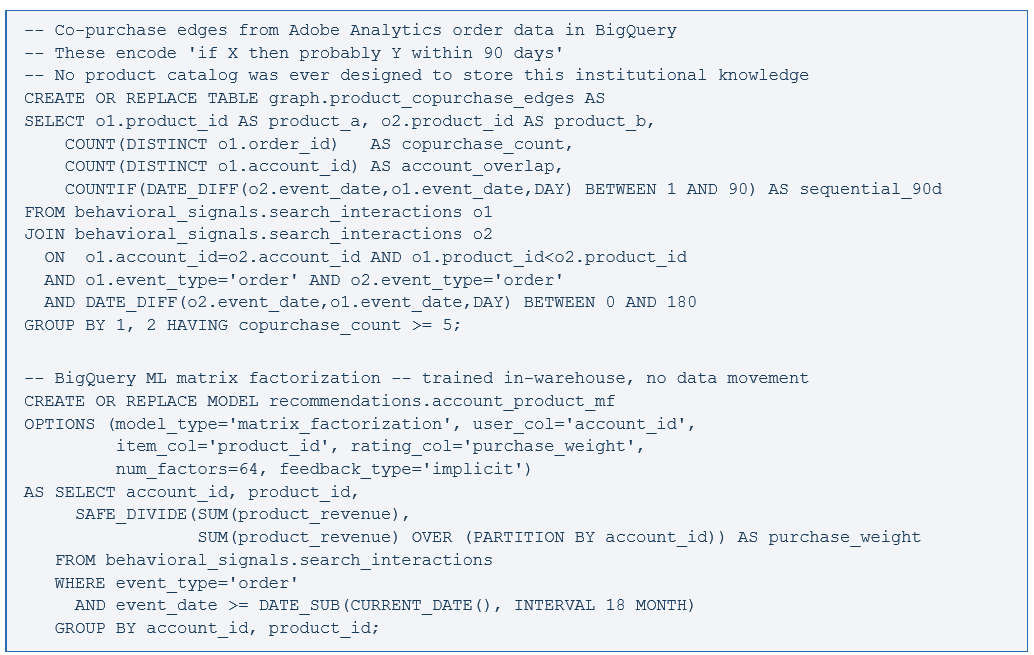
The fix is Domain-Adaptive Pre-training. Take the base model and keep training it on your domain corpus — product data sheets, SKU attribute tables, compatibility matrices, manufacturer spec documents, and historical purchase sequences from BigQuery. The training objective is triplet loss:

The hard negatives are everything. Random negatives produce weak signal. Adobe Analytics hands the hard negatives directly to you — products shown in top-5 positions that buyers rejected. That is the signal that makes fine-tuning effective.
Gemini Flash as the Query Translation Layer
Gemini Flash is not the search engine. It is the query translator. The difference matters.
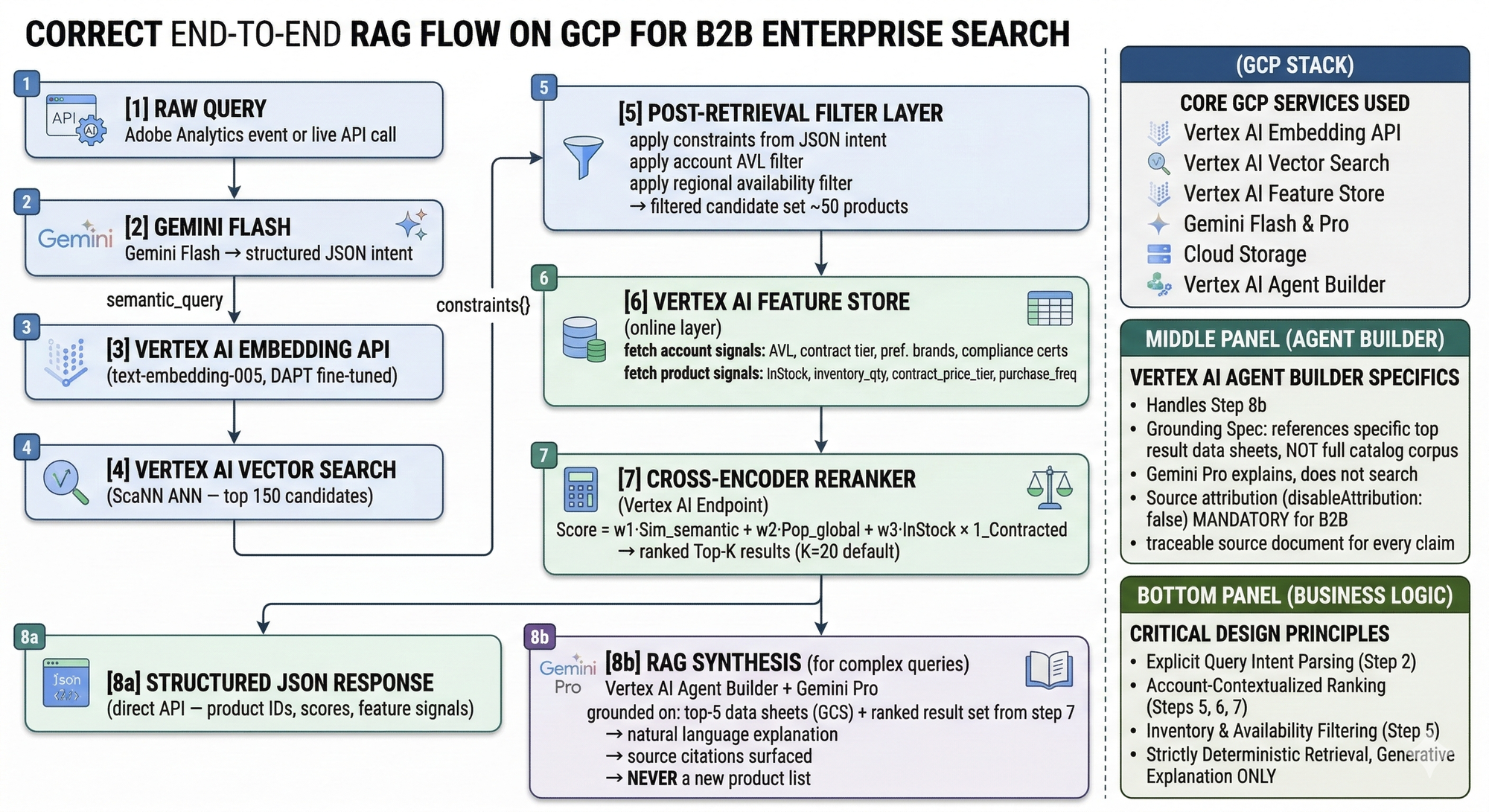
A buyer types: "need something to replace our aging NetScaler ADC fleet without a full rearchitecture." A tokenization-based parser drops rearchitecture as unknown vocabulary and returns Citrix ADC products sorted by popularity. The migration constraint — the whole point of the query — is completely gone. Gemini Flash, with account context injected at runtime from Feature Store, returns structured JSON the retrieval and ranking layers can actually execute against.

The semantic_query field feeds Vertex AI Embedding and then Vector Search. The constraints object becomes the post-retrieval filter. The account_filter block tells the reranker how to apply the contracted vendor boost. Full round-trip — Gemini Flash, embedding, ANN query — runs at about 180ms end-to-end when Vertex AI endpoints are in the same region as your serving infrastructure.
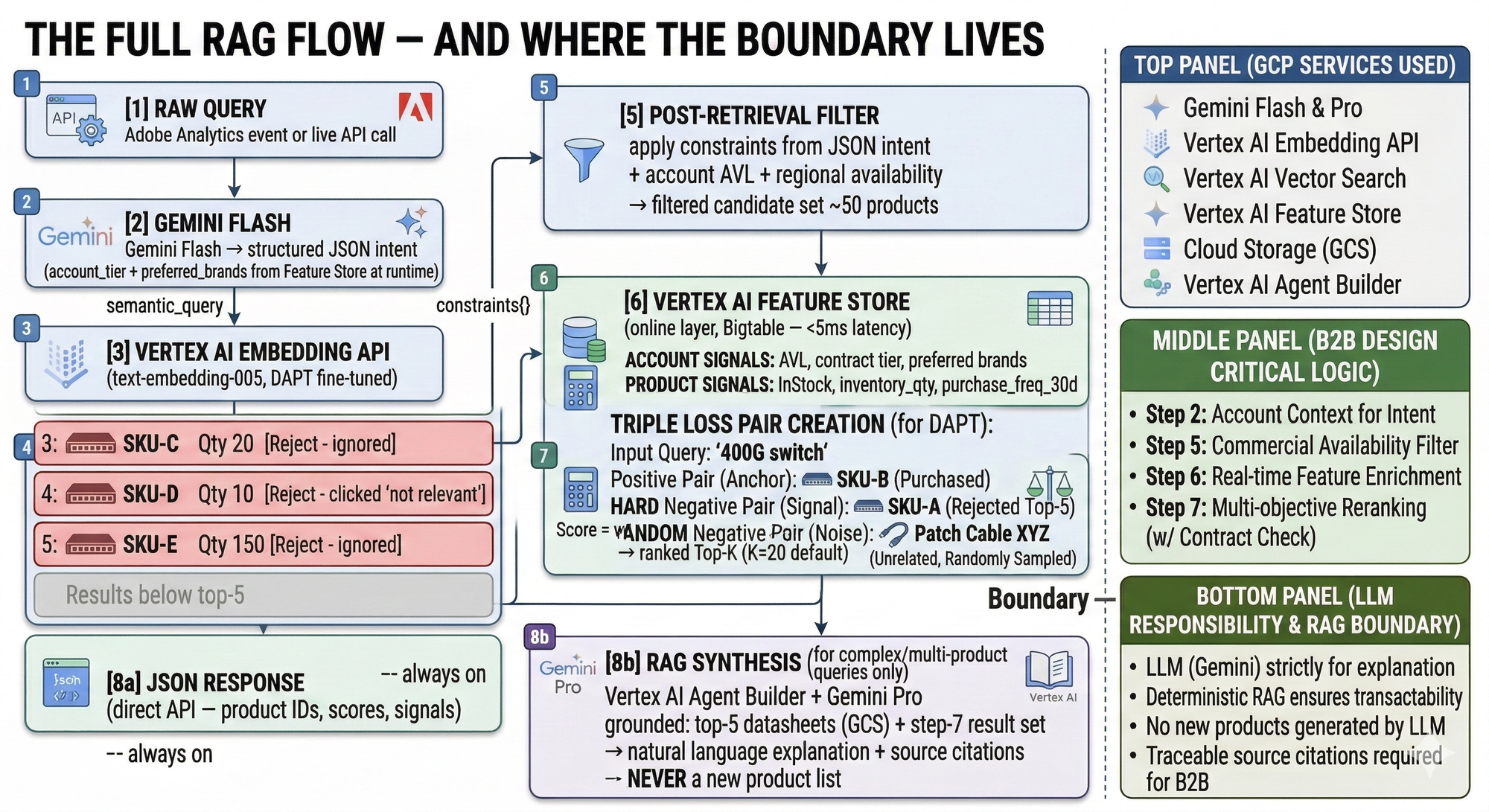
The groundingSpec in Agent Builder must reference product datasheets from the top results — not the full catalog corpus. You are asking Gemini to explain results the deterministic pipeline already retrieved and ranked. Source attribution on (disableAttribution: false) is mandatory. In enterprise procurement, a generated claim without a traceable source document is a compliance and audit risk.
The Ranking Formula — and the Feature Store Work Behind It

That 1_Contracted term is where most B2B search systems have nothing at all. It is also the single highest-leverage signal in the formula. We saw this in our account-tier cohort analysis: Gold-tier accounts had materially higher conversion when contracted products ranked in positions 1-3. When ranking ignored contract status, Gold accounts converted at barely above Silver rates. The contract signal was worth more than any amount of semantic tuning.
The preferred_brands feature is derived from Adobe Analytics — not manually configured by account managers. Brands whose product pages a given account visits most frequently, recency-weighted, normalized across the full interaction history. It is one of the most practically useful signals we have, and it costs nothing to produce once the AA pipeline is running.
Feature freshness is the operational challenge nobody fully appreciates until a production incident. Monitor the Dataflow pipeline health separately from the model. A stale feature is worse than no feature. It corrupts the ranking signal silently. The model has no way to know its inputs are wrong.
The Recommendation Layer — Procurement Logic Lives in a Graph
Standard collaborative filtering fails in B2B for a structural reason: the unit of procurement behavior is the account, not the user. We ran matrix factorization on user IDs first. The results were mediocre. When we rebuilt on account IDs, attach rate improved measurably. Not a model improvement — a modeling unit improvement.
Measuring What Actually Matters
This is the dashboard that replaced NDCG as our primary signal for search health. Everything sources from Adobe Analytics via BigQuery.

Four numbers I check every Monday morning: search conversion rate by account tier (Gold should be materially above Silver — if not, the 1_Contracted signal is degrading), retrieval success rate (below 85% kicks off the triplet mining pipeline), average query reformulations by category (rising in a specific category means the vocabulary gap is widening there), and recommendation attach rate versus baseline (the number that makes the business case for the procurement graph).
What Breaks in Production — Specifically
The eVar reassignment you did not catch
Add the NULL rate validation to Dataflow, set an alert threshold, treat a spike in NULL query_raw values as a sev-2 incident. It is data pipeline corruption that silently poisons your training data for weeks before anything surfaces in model metrics. Build this before you need it. We built it after.
The embedding drift you will not notice until it is bad
The DAPT model was trained on catalog data from a point in time. Six months later, the catalog has changed and the model has not. The retrieval success rate metric is the only early warning system. If you do not have it instrumented, you will find out about embedding drift from a revenue conversation, not a technical alert. I have been in that revenue conversation. It is not how you want to find out.
The Feature Store pipeline nobody monitors
Every team monitors model serving infrastructure. Few monitor feature freshness. The inventory signal refreshes every five minutes — until the Dataflow job fails transiently for three hours and nobody notices, and the ranking layer serves stale inventory through a peak ordering window. A monitoring query on the Feature Store last-updated timestamp, alerting if stale more than ten minutes, takes an afternoon to build. Do it before the incident, not after.
The A/B test that measured CTR instead of conversion
We ran this mistake. I described the room I was sitting in. Fix: instrument the A/B test against search_conversion_rate, not CTR. The test will need to run longer on sparse B2B conversion events. Run it longer. The metric you choose determines what the model learns to optimize for.
Where Agentic Search Actually Sits Right Now
The vision I am working toward: a buyer describes their full infrastructure build in natural language, and the system assembles a complete, compatibility-checked, AVL-filtered, contract-priced bill of materials ready for procurement approval. No reformulations, no manual cross-referencing, no calls to a rep to confirm compatibility.
The architecture described here is precisely what that agentic layer depends on at runtime. The agent is only as smart as the data it can call. If the features are stale, the embeddings are generic, and the behavioral signals are not in BigQuery, the agent produces confident-sounding answers grounded in nothing. I have seen this. It is worse than no agent.
We are building toward agentic capability in staged increments: behavioral pipeline shipped, domain embeddings running, account-contextualized ranking in production, RAG synthesis for complex queries rolling out. Teams that try to build the agent first consistently end up back at the foundation six months later, with more technical debt and a harder conversation to have with stakeholders.
The Part Not on Any Architecture Diagram
The Adobe Analytics implementation that feeds all of this needs ongoing, deliberate maintenance. When a new feature launches, the tagging spec needs updating before launch — not two weeks after when you notice the data gap. When an eVar gets repurposed, the Dataflow mapping changes in the same sprint. When a new product category is onboarded with different terminology conventions, the triplet mining query needs a coverage check. None of this is automatic.
The technology described here is real and deployed, and well-supported by GCP. The discipline to operate it — to maintain the data contracts, to run properly powered A/B tests against conversion metrics, to retrain on schedule rather than when someone complains — that is the compounding advantage. The companies that have built it right are genuinely hard to displace. Not because of the model. Because of the years of behavioral signal in BigQuery, the fine-tuned embeddings, the procurement graph. You cannot copy that stack. Start with the Adobe Analytics pipeline. Everything else follows.
—This architecture is production-tested and the metrics are real. If you are building something similar, have pushed this further, or want to go deeper on any piece of it — connect on LinkedIn or reach out directly. The most useful conversations I have had always start with someone who has shipped something and has opinions about what I got wrong.—